All Large language models such as GPT and Llama are trained with a next-token prediction loss. However, despite the recent wave of impressive achievements in LLMs, next-token prediction remains an inefficient way of acquiring language, world knowledge and reasoning capabilities. More precisely, LLM training are more focus on next-token prediction based on local patterns and overlooks “hard” decisions.
So is there any way we can improve next-token prediction capabilities of LLMs without any additional training ?
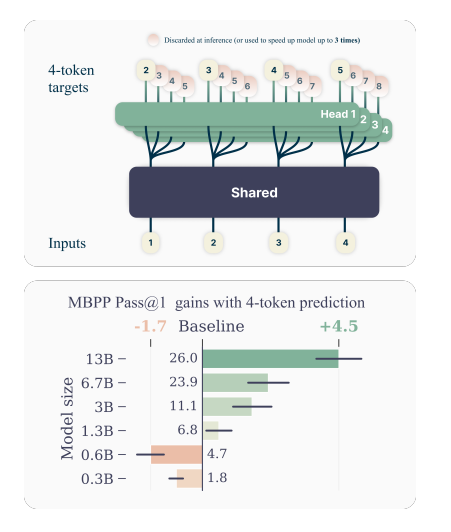
It looks like AI @ Meta has a solution for it by moving away from traditional next-token prediction to a multi-token prediction strategy, demonstrating that LLMs can achieve better outcomes without additional training time. In order to do so Meta has introduced multi-token prediction architecture with no train time or memory overhead. During training, the model predicts 4 future tokens at once, by means of a shared trunk and 4 dedicated output heads. During inference, it employs only the next-token output head. Optionally, the other three heads may be used to speed-up inference time.
One big challenge in training multi-token predictors is reducing their GPU memory utilization. To overcome this Meta multi-tone prediction architecture carefully adapt the sequence of forward and backward operations. By performing the forward/backward on an n-token prediction model with n = 2 heads in sequential order, it avoids materializing all unembedding layer gradients in memory simultaneously and reduces peak GPU memory usage. During inference multiple independent output heads of the architecture, each predicting a future token, allowing parallel token prediction there by speed up decoding from the next-token prediction head with self-speculative decoding methods such as blockwise parallel decoding.
During evaluation, 13B models trained on multi-token prediction architecture solved 12 % more problems on HumanEval and 17 % more on MBPP than comparable next-token models. Experiments on small algorithmic tasks demonstrate that multi-token prediction is favorable for the development of induction heads and algorithmic reasoning capabilities. As an additional benefit, models trained with 4-token prediction are up to 3× faster at inference, even with large batch sizes.
Paper : https://arxiv.org/pdf/2404.19737